YouTube has received criticism for the video recommendations it gives after a user watches a video on the site. Critics allege that YouTube has prioritized viewership and engagement over all else. As a result, recommended videos are often more controversial than a viewer’s initial search and likely to contain misleading if not out-right incorrect claims. YouTube claimed to have addressed these issues earlier in 2019, but I wanted to see if this was the case utilizing machine learning, specifically natural language processing and topic analysis.
Data Collection Infrastructure
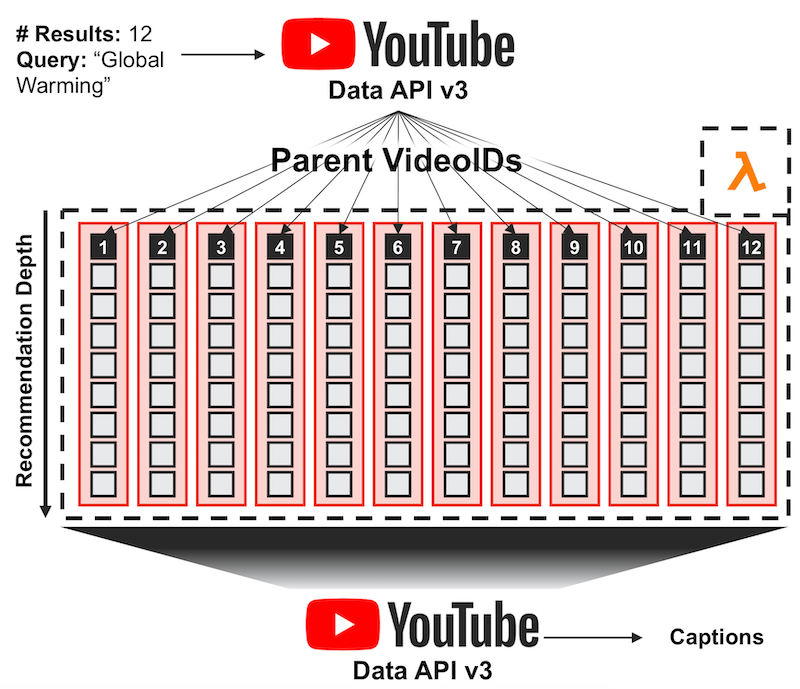
I needed a collection of video transcripts from YouTube for natural language processing. This part is fairly trivial as YouTube provides transcript access through their API. The the main difficulty is getting the right transcripts. I wanted to get transcripts of videos that were recommended off of some initial YouTube video.
For my datasets, I collected 50 initial videos by searching a term on YouTube (through their API) and then “clicking through” 19 subsequent video recommendations for each of the initial videos to generate an array of 20x50 videos. Where the length 20 axis represents recommendation depth and the length 50 axis represents 50 independent “viewing sessions”. 50 sessions were chosen to get some variance in starter video and to get a greater number of documents for NLP. YouTube does not allow you to get a list of recommendations from their API, so I had to devise a webscaper to do this part.
AWS Lamda
I decided to use AWS Lambda to deploy my webscraper as I thought the service would be perfect for asynchronous tasks that as a result could be executed in parallel. AWS Lambda is a serverless Amazon product where user-supplied “Lambda” functions (nothing to do with pythonic lambda function) can be ran as a consequence of user requests or invoked by other lambda functions. In this case, I wanted to run 50 webscraper functions in parallel, one for every initial video, which would then “click through” each recommended video and return a list of 20 video IDs.
I designed two lambda functions for my webscraper. The first would generate a list of 50 video IDs by searching a user-supplied term via YouTube’s API. This function would fire off 50 webscapers (my second function) for each of the 50 videos through asynchronous invocation. This second function would take the video ID supplied by the first function and find the next 19 video IDs using a headless chrome browser and selenium. This list of video IDs was then added to a Mongo database housed in an EC2 instance along with some meta-data to link the 50 websraper requests together.
The notebook aws_requests.ipynb contains the two lambda functions along with user invocation of the first via Amazon’s boto3 Python package.
Transcript Collection
Once the video IDs were collected, transcripts were requested with the YouTube Transcript API Python package, which helps streamline this particular request. These transcripts were stored in the Mongo Database with their corresponding video ID.
The diagram below depicts the full request process for a “global warming” query.
Natural Language Processing
As both a learning excercise and to better justify my results, I wanted to find the combination of NLP techniques that best worked on my YouTube transcript corpus. I decied to try out different combinations of topic analysis, tokenizer, stemmer and tokenizer and evaluate the output in a simple naive bayes classifcation model and a knn clustering model. I had 600 different combinations of NLP techniques to try, so I incorporated this NLP pipeline class framework to manage testing.
NLP Pipeline Evaluation
In order to determine the best NLP pipeline (a unique combination of topic analysis, tokenizer, stemmer and tokenizer) I needed a labeled dataset of YouTube transcripts. I generated this by doing “shallow” searches of YouTube videos where I took only the initial video and immediate recommendation. I did this for 4 different search terms to generate a 400 video dataset where the labels were the search terms; the idea being that I should be able to match a video back to its search term using NLP if my pipeline could effectively characterize YouTube transcript text.
I split my 400 video labeled dataset into a training and test set. For each pipeline, I generated 8 different topics on the training set and calculated each video’s proportion of the 8 topics. The output of this was used to fit my clustering and classifcation models. I scored the clustering model using accuracy. Since my labels were balanced (I had ~100 of each) and I placed no great importance on getting one label right over another, I felt accuracy was an appropriate metric here. I used an adjusted rand index to evaluate my clustering model. The adjusted rand index is similar to accuracy, but is used for clustering models where labels are available. The rand index measures all observation pairs in a predicted set of labels and a corresponding actual set of labels and counts the number of pairs that are in the same cluster or in different clusters in both datasets. This allows you to generate something akin to accuracy without having to tell the clustering model which cluster corresponds to which original label. The adjusted part of the rand index is used to account for the natural variation in the dataset where a score of 0 represents a Rand Index calculated for a randomly generated set of predicted labels.
The table below shows the top 20 pipelines by adjusted rand index. I believed this to be the better score for model selection as most of the classification models were able to achieve a high degree of accuracy and the pipeline would ultimately be used for unlabeled data. I opted to use the first model shown and I have included a quick description of each of the pipeline pieces below:
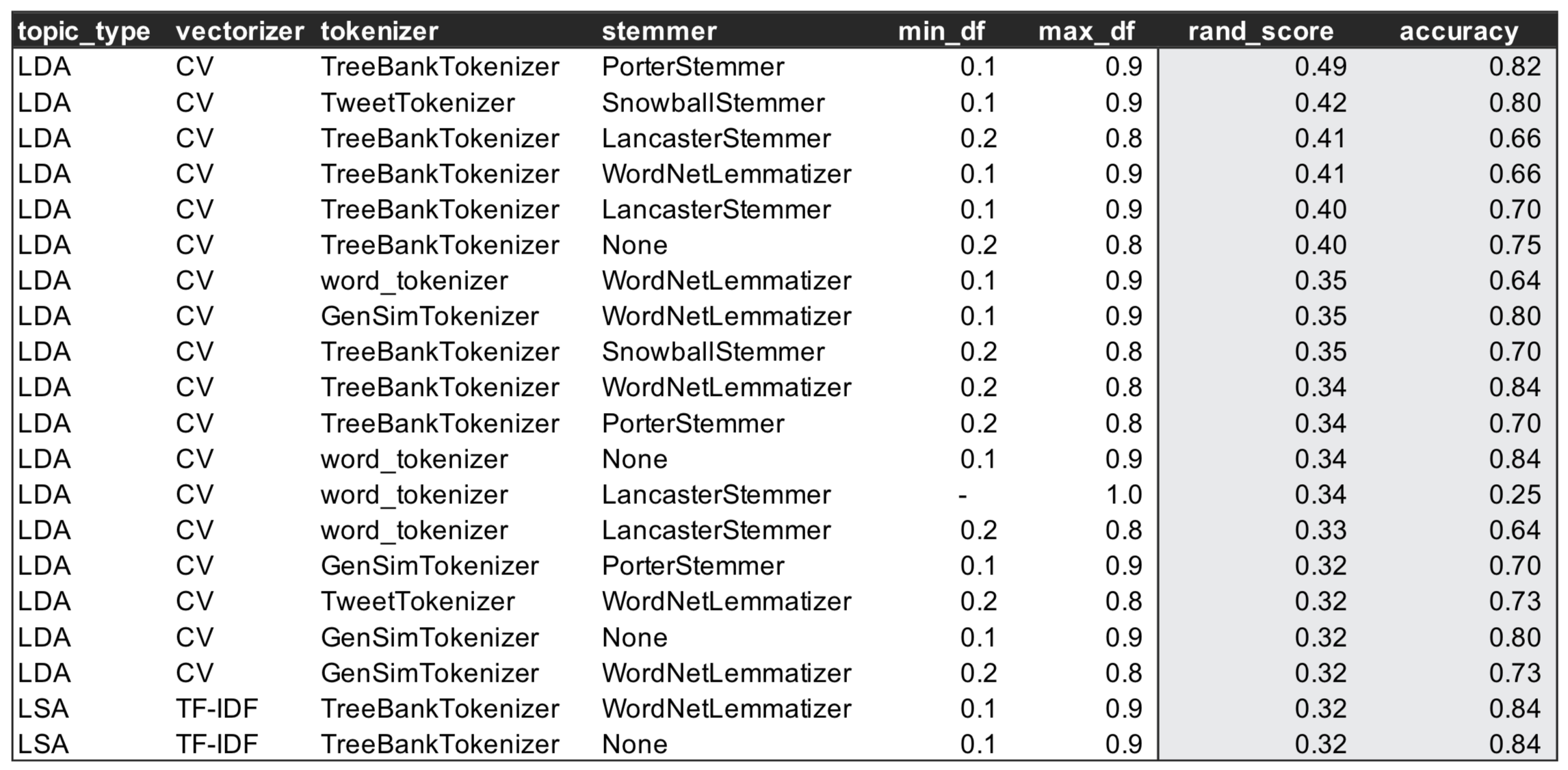
Selected Pipeline:
- Latent Dirichlet Allocation (LDA): LDA assumes that each document (transcript in our case) can be modeled as a distribution of topics, with each topic represented as a distribution of words. It randomly assigns words to topics and topics to words and then recalculates these assignments based on the actual distribution of words in the corpus until a steady state is reached or some calculation limit is hit.
- Count Vectorizer (CV): CV takes a list of tokens (can be thought of as words) for each document and converts that into a matrix where each row represents a document and each column represents the number of occurances of a given word per document. An alternative vectorizer is term frequency-inverse document frequency or TF-IDF, which divides the count of words (term frequency) by the number of documents which contain a word, effectively giving weight to rarer words.
- TreeBank Tokenizer: Converts documents into a list of tokens. The TreeBank tokenizer will split contractions into their base word and modifier such as “can’t” into “can” and “‘t”.
- Porter Stemmer: Removes suffixes from words. This is useful as there is a huge number of unique words in the corpus.
- 10% Minimum Document Frequency: Tokens that show up in less than 10% of documents are not counted.
- 90% Maximum Document Frequnecy: Tokens that show up in more than 90% of documents are not counted.
Topic Modeling Results
The selected pipeline was than applied to a set of YouTube video transcripts generated from the Lambda webscraping functions. I could then take the average topic composition for all videos for a given recommendation depth and plot this for all depths to generate a stacked area plot. The plot below is an example of one generated from “Donald Trump Rally” as the search term. I have also highlighted some of the more interesting topics to the right of the plot. Please see my full presentation here for an exhaustive list of topics.
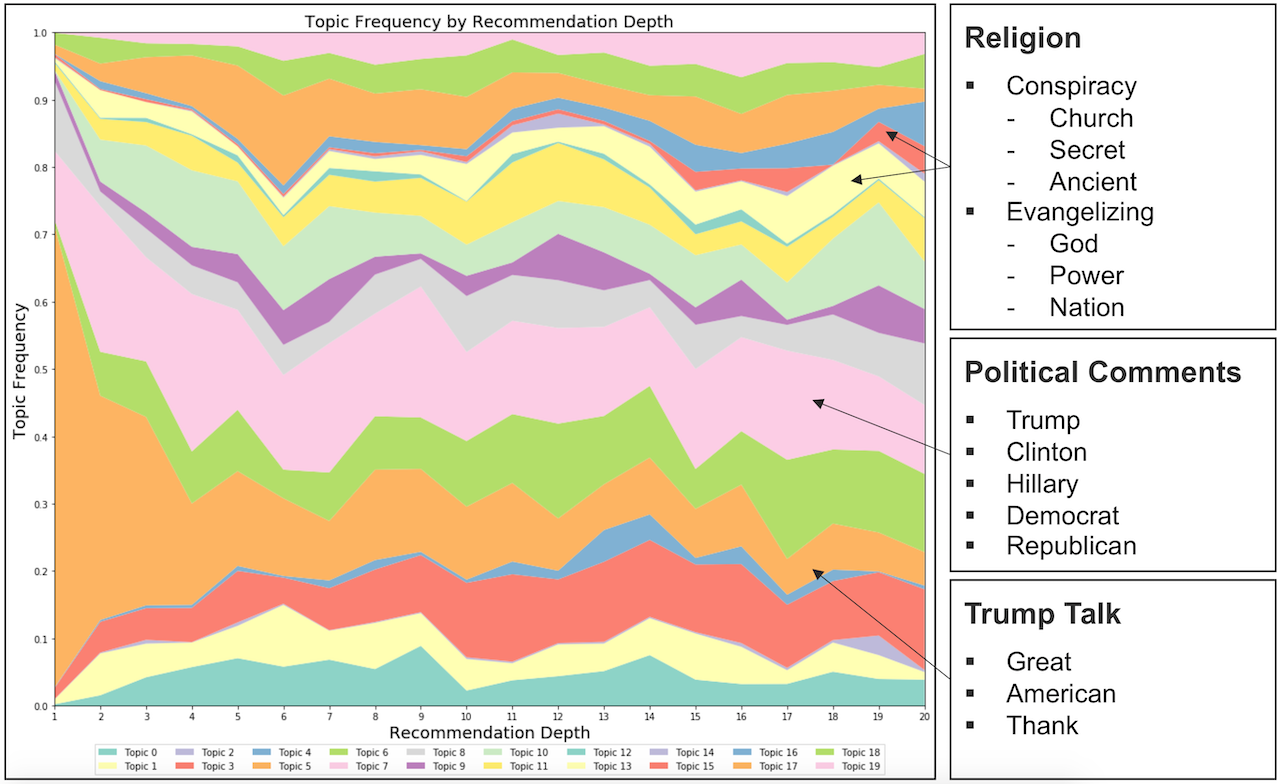
It does appear that the content of YouTube videos does change with recommendation depth, however many of these changes are benign. For example, initial videos from the rally search are actual rally recordings which then give way to general videos discussing American politics from major news outlets. This seems to be a logical and responsible recommendation given the initial political slant of the search. However, as highlighted in the plot, some recommendations do turn to more controversial topics such as a fundamentalist Christian discussion of American politics (see the evangelizing topic).